Large language models like GPT family are decoder-only transformers that learn to predict the next token in a sequence. During pretraining, the model is exposed to a large corpus of unlabelled text and optimises a next-token prediction objective. This post will focus on pretraining GPT on a training corpus of only 5,145 tokens, which is far too small to produce a useful model. Therefore, this is better served as a proof-of-concept. Nevertheless, the code is extremely versatile and can be applied to continually pre-train other open-weight large language models. At the end of the notebook, we will load the pre-trained weights of the GPT-2 to inspect it further.
Although real pretraining is computationally intensive, understanding the mechanics of the code helps demystify language-model training. This post reviews the important functions from a simplified GPT pretraining loop, explains their purpose, and demonstrates their behaviour using a minimal implementation based on NumPy and PyTorch.
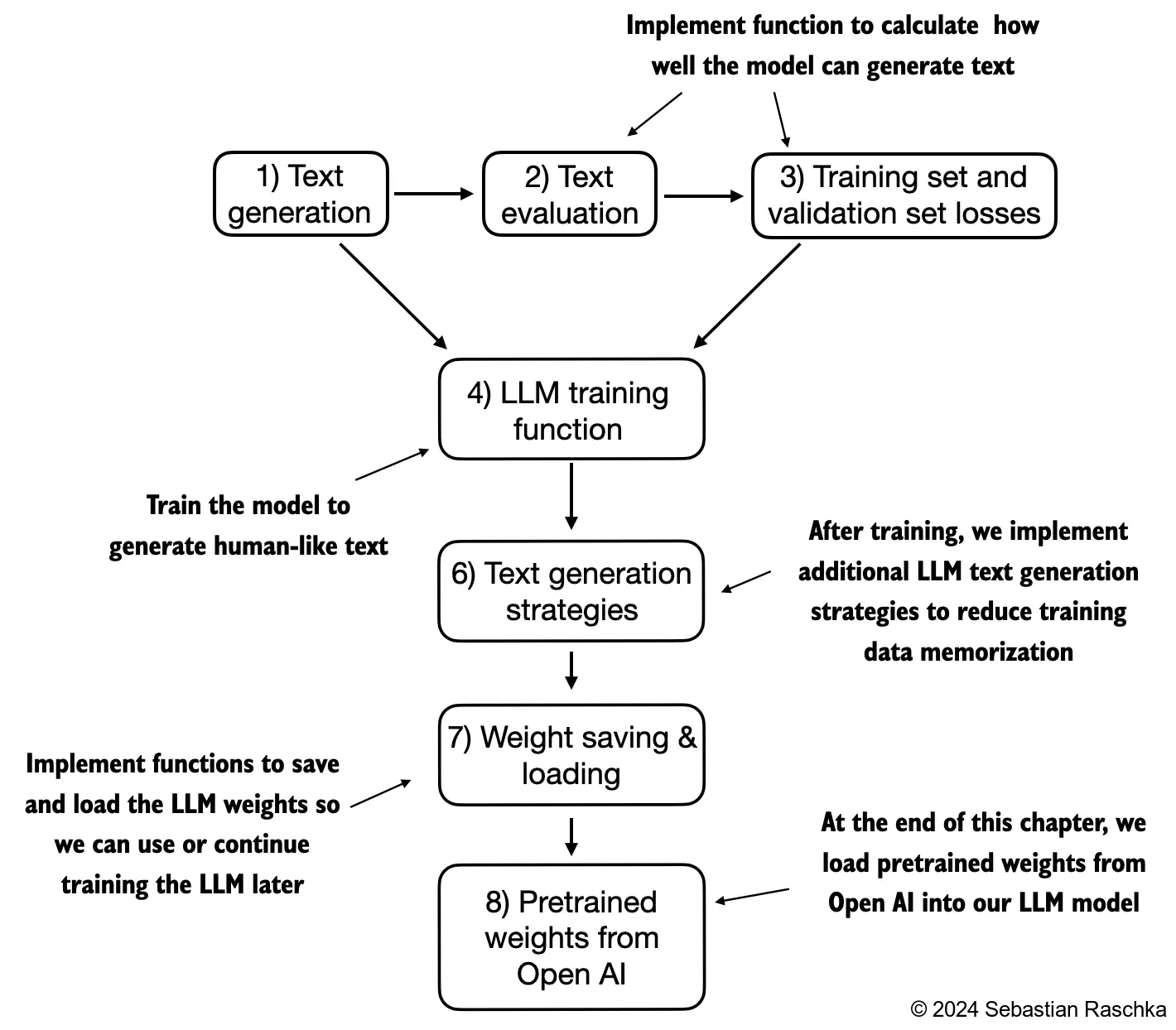
The following is the complete pipeline of what we are going to do:
Firstly, let's initialize our untrained GPT model, whose complete architecture we have built from scratch.
import torch
from previous_chapters import GPTModel
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 256, # Shortened context length (orig: 1024)
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-key-value bias, it is worth noting that modern LLMs do not use this anymore
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval(); # Disable dropout during inferenceLet's also show the dataset that we are going to be using
import os
import urllib.request
file_path = "the-verdict.txt"
url = "https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt"
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode('utf-8')
with open(file_path, "w", encoding="utf-8") as file:
file.write(text_data)
else:
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()Next, we will use the generate_text_simple() function to generate texts and two helper functions for converting between tokens and text representations. The last row vector is actually the new word generated (with the agrmax probability).
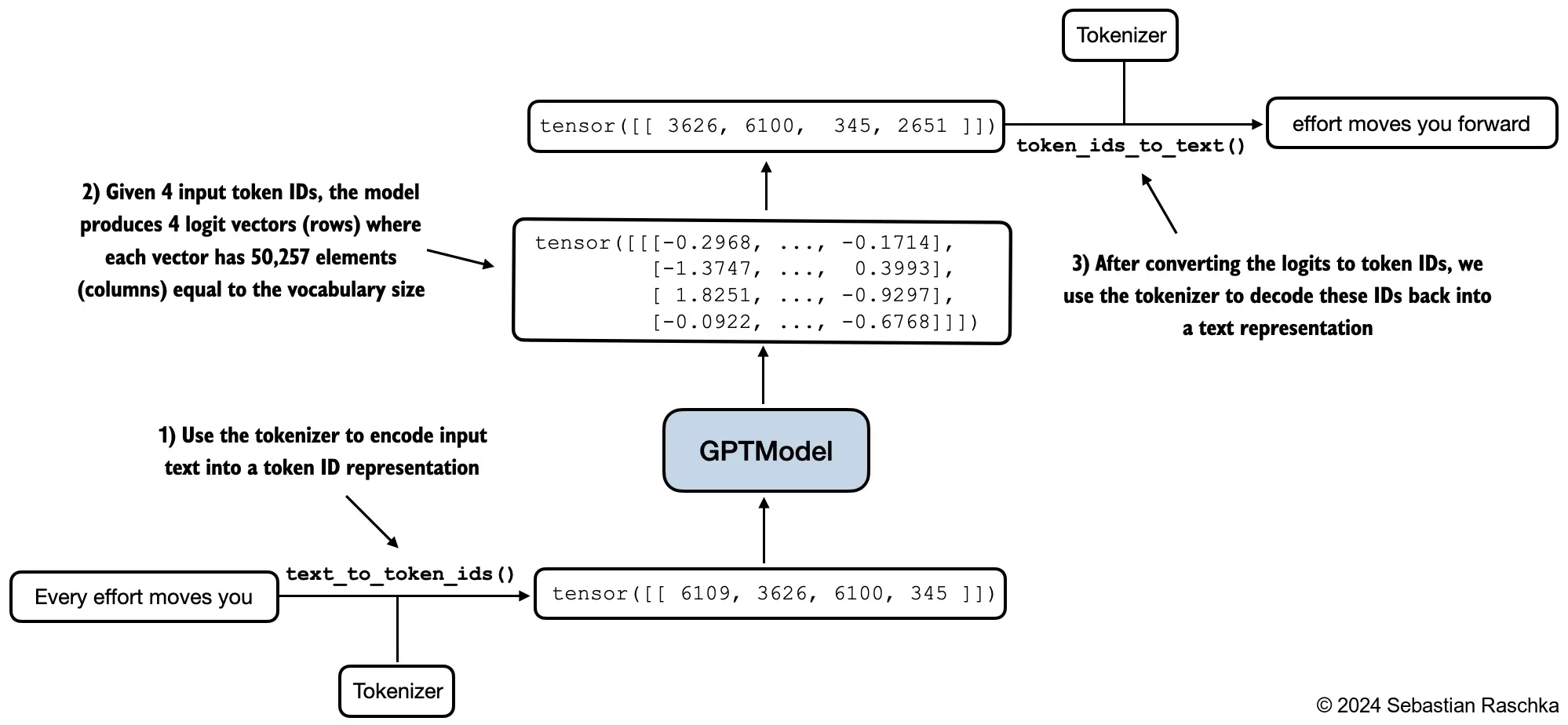
import torch
# Greedy decoding (generating text)
def generate_text_simple(model, idx, max_new_tokens, context_size):
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:] # (batch_size, n_tokens)
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :] # focus on only the last timestep
probas = torch.softmax(logits, dim = -1) # (batch_size, vocab_size)
idx_next = torch.argmax(probas, dim=-1, keepdims=True) # (batch_size, 1)
idx = torch.cat((idx, idx_next), dim=1) # (batch_size, n_tokens+1)
return idx
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # Add batch dimension
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0)
text = tokenizer.decode(flat.tolist())
return text
start_context = "Every effort moves you"
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(start_context, tokenizer),
max_new_tokens=10,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
# Every effort moves you rentingetic wasnم refres RexMeCHicular strenAs we can see, the model produces incoherent text simply because it has not been trained yet. However, how do we even measure or capture what coherent text is numerically? The answer lies in understanind the cross-eontrpy, which is the difference between two probability distributions. The closer the difference is to 0, the more aligned between the actual distribition of word and the empirical distribution (the model's predictions).

It is, from my own obervation, extremely important to understand that real effective models produce much larger losses at the start of training and gradually reduce them as the weights update. If the loss goes down too much like a slope, it might actually be overfitting and producing non-sensical such as repeated texts.
# utility functions to calculate the cross-entropy loss for a given batch
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(
logits.flatten(0, 1),
target_batch.flatten()
)
return loss
# a second utility function to compute the loss for a user-specified number of batches in a data loader
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0.
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
# Reduce the number of batches to match the total number of batches in the data loader
# if num_batches exceeds the number of batches in the data loader
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
else:
break
return total_loss / num_batchesOverall, we want to maximize the probability associated with the target words and minimize the probabilities corresponding to the incorrect words. Another concept related to the cross-entropy loss the perplexity. It is usually considered more intepretable since it can be seen as the effective vocabulary size that the model is uncertain about at each step. In other words, perplexity provides a measure of how well the probability distribution predicted by the model matches the actual distribution of the words in the dataset.
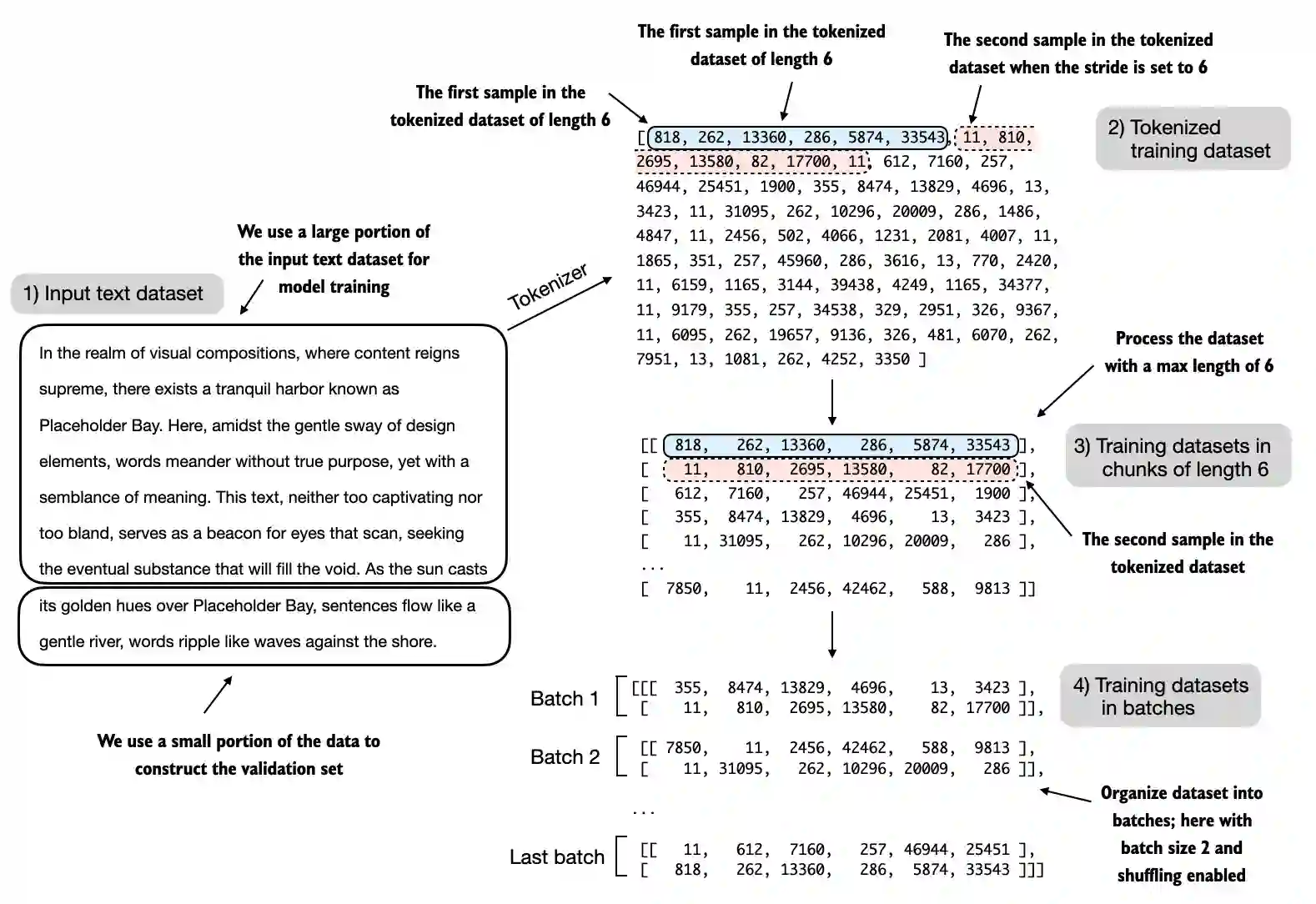
Segmenting Text into Training Sequence. GPT models often expect a fixed context length, typically 512-1024 tokens for small models. Longer texts must be broken into overlapping segments so that each sample contains max_length tokens and the model always has enough context for prediction. The GPTDatasetV1 class iterates over the long tokenised sequence with a sliding window and stride, creating input–target pairs. After splitting into segments, the targets are simply the inputs shifted by one position because the model is trained to predict the next token.
import torch
from torch.utils.data import Dataset, DataLoader
import tiktoken
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
token_ids = tokenizer.encode(txt)
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i : i + max_length]
target_chunk = token_ids[i + 1 : i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader_v1(txt, batch_size=4, max_length=256, stride=128, shuffle=True, drop_last=True, num_workers=0):
tokenizer = tiktoken.get_encoding("gpt2")
dataset = GPTDatasetV1(
txt,
tokenizer,
max_length,
stride
)
dataloader = DataLoader(
dataset,
batch_size = batch_size,
shuffle = shuffle,
drop_last = drop_last,
num_workers = num_workers,
)
return dataloaderA dataloader groups these samples into batches. Because the toy dataset is tiny, our demonstration uses a batch size of 2, producing one batch of shape (2, 6) for both inputs and targets. In real pretraining, larger batch sizes improve training stability and throughput. Small batches are often chosen when the dataset or compute resources are small.
Finally, let's split into train/val/test sets and carry out some sanity checks
# Train/validation ratio
train_ratio = 0.90
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
torch.manual_seed(123)
train_loader = create_dataloader_v1(
train_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=True,
shuffle=True,
num_workers=0
)
val_loader = create_dataloader_v1(
val_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=False,
shuffle=False,
num_workers=0
)The first check is to check the size and shape of the data loaders
print("Train loader:")
for x, y in train_loader:
print(x.shape, y.shape)
print("\nValidation loader:")
for x, y in val_loader:
print(x.shape, y.shape)
'''
Train loader:
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
Validation loader:
torch.Size([2, 256]) torch.Size([2, 256])
'''The second sanity check is the number of tokens that we are going to pre-train. For pre-training specfically, the metric is often the number of tokens whereas in finetuning, it is more about the size of the training dataset.
train_tokens = 0
for input_batch, target_batch in train_loader:
train_tokens += input_batch.numel()
val_tokens = 0
for input_batch, target_batch in val_loader:
val_tokens += input_batch.numel()
print("Training tokens:", train_tokens)
print("Validation tokens:", val_tokens)
print("All tokens:", train_tokens + val_tokens)
'''
Training tokens: 4608
Validation tokens: 512
All tokens: 5120
'''The final check is to compute the loss of the baseline models and try inferencing on it
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
torch.manual_seed(123)
with torch.no_grad(): # Disable gradient tracking for efficiency because we are not training, yet
train_loss = calc_loss_loader(train_loader, model, device)
val_loss = calc_loss_loader(val_loader, model, device)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
'''
Training loss: 10.98758347829183
Validation loss: 10.98110580444336
'''The Training Loop. Believe it or not, the training part is actually the easiest one if we are also well-versed on how to sample the data and construct the evaluation pipeline (after several sanity checks too!). If you are working with the transformers package, the training can be done in one simple code cell. However, since I am trying to code everything from scratch, I will break down the training loop into individual parts to clearly get a grasp on how the model actually gets better.
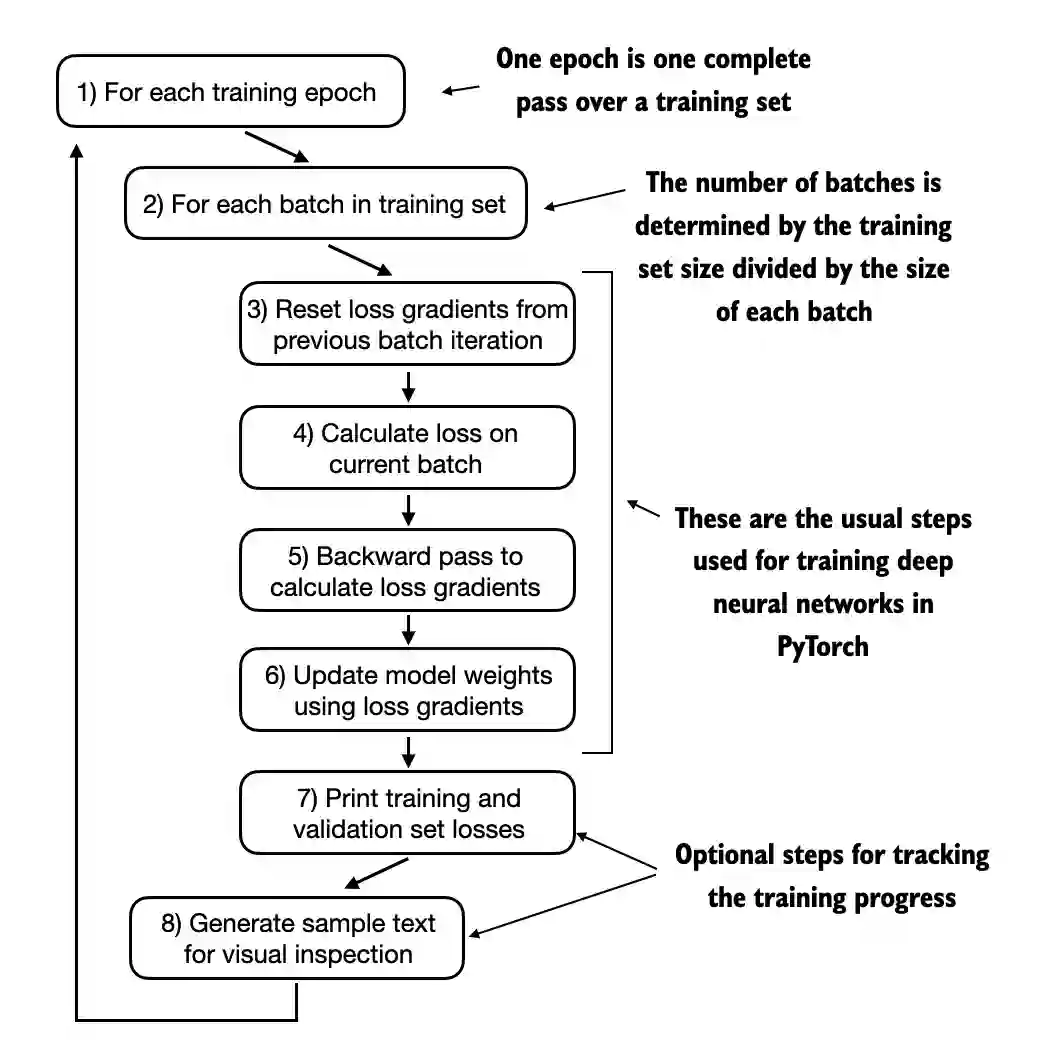
The train_model_simple function orchestrates the training process. For each batch it zeroes out gradients, computes the loss via calc_loss_batch, performs back-propagation (loss.backward()), and updates the model parameters with the optimiser. It also keeps track of the total number of tokens processed and periodically evaluates the training and validation losses using evaluate_model.
The evaluation function sets the model to evaluation mode, averages the loss over a specified number of batches and switches the model back to training. The notebook’s training loop prints the average training and validation loss every few steps and then generates a sample of text after each epoch. In the example run, both losses steadily decrease and the generated text improves over epochs, demonstrating that even a small model can learn a short corpus.
Implementing a full training loop requires automatic differentiation and GPU acceleration, which are not available in this environment. However, the conceptual structure remains the same: iterate over batches, compute loss and gradients, update parameters, occasionally evaluate on held-out data, and sample generated text to monitor qualitative progress.
# training loop
def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
# Initialize lists to track losses and tokens seen
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
# Main training loop
for epoch in range(num_epochs):
model.train() # Set model to training mode
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # Reset loss gradients from previous batch iteration
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward() # Calculate loss gradients
optimizer.step() # Update model weights using loss gradients
tokens_seen += input_batch.numel()
global_step += 1
# Optional evaluation step
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")
# Print a sample text after each epoch
generate_and_print_sample(
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
model.eval()
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
model.train()
return train_loss, val_loss
# sampling function using greedy decoding
def generate_and_print_sample(model, tokenizer, device, start_context):
model.eval()
context_size = model.pos_emb.weight.shape[0]
encoded = text_to_token_ids(start_context, tokenizer).to(device)
with torch.no_grad():
token_ids = generate_text_simple( # greedy decoding
model=model,
idx=encoded,
max_new_tokens=50,
context_size=context_size
)
decoded_text = token_ids_to_text(token_ids, tokenizer)
print(decoded_text.replace("\n", " ")) # Compact print format
model.train()Let's train on our small dataset
import time
start_time = time.time()
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)
num_epochs = 10
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context="Every effort moves you", tokenizer=tokenizer
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")
'''
Ep 1 (Step 000000): Train loss 9.781, Val loss 9.933
Ep 1 (Step 000005): Train loss 8.111, Val loss 8.339
Every effort moves you,,,,,,,,,,,,.
Ep 2 (Step 000010): Train loss 6.661, Val loss 7.048
Ep 2 (Step 000015): Train loss 5.961, Val loss 6.616
Every effort moves you, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and,, and, and,
Ep 3 (Step 000020): Train loss 5.726, Val loss 6.600
Ep 3 (Step 000025): Train loss 5.201, Val loss 6.348
Every effort moves you, and I had been.
Ep 4 (Step 000030): Train loss 4.417, Val loss 6.278
Ep 4 (Step 000035): Train loss 4.069, Val loss 6.226
Every effort moves you know the "I he had the donkey and I had the and I had the donkey and down the room, I had
Ep 5 (Step 000040): Train loss 3.732, Val loss 6.160
Every effort moves you know it was not that the picture--I had the fact by the last I had been--his, and in the "Oh, and he said, and down the room, and in
Ep 6 (Step 000045): Train loss 2.850, Val loss 6.179
Ep 6 (Step 000050): Train loss 2.427, Val loss 6.141
Every effort moves you know," was one of the picture. The--I had a little of a little: "Yes, and in fact, and in the picture was, and I had been at my elbow and as his pictures, and down the room, I had
Ep 7 (Step 000055): Train loss 2.104, Val loss 6.134
Ep 7 (Step 000060): Train loss 1.882, Val loss 6.233
Every effort moves you know," was one of the picture for nothing--I told Mrs. "I was no--as! The women had been, in the moment--as Jack himself, as once one had been the donkey, and were, and in his
Ep 8 (Step 000065): Train loss 1.320, Val loss 6.238
Ep 8 (Step 000070): Train loss 0.985, Val loss 6.242
Every effort moves you know," was one of the axioms he had been the tips of a self-confident moustache, I felt to see a smile behind his close grayish beard--as if he had the donkey. "strongest," as his
Ep 9 (Step 000075): Train loss 0.717, Val loss 6.293
Ep 9 (Step 000080): Train loss 0.541, Val loss 6.393
Every effort moves you?" "Yes--quite insensible to the irony. She wanted him vindicated--and by me!" He laughed again, and threw back the window-curtains, I had the donkey. "There were days when I
Ep 10 (Step 000085): Train loss 0.391, Val loss 6.452
Every effort moves you know," was one of the axioms he laid down across the Sevres and silver of an exquisitely appointed luncheon-table, when, on a later day, I had again run over from Monte Carlo; and Mrs. Gis
'''It is also conventional to plot out the losses to visualize it better
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
fig, ax1 = plt.subplots(figsize=(5, 3))
# Plot training and validation loss against epochs
ax1.plot(epochs_seen, train_losses, label="Training loss")
ax1.plot(epochs_seen, val_losses, linestyle="-.", label="Validation loss")
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.legend(loc="upper right")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True)) # only show integer labels on x-axis
# Create a second x-axis for tokens seen
ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis
ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks
ax2.set_xlabel("Tokens seen")
fig.tight_layout() # Adjust layout to make room
plt.savefig("loss-plot.pdf")
plt.show()
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)Looking at the results above, we can see that the model starts out generating incomprehensible strings of words, whereas towards the end, it is able to produce grammatically more or less correct sentences.
Based on the training and validation set losses, we can see that the model starts overfitting. That said, if we were to check a few passgaes it writes towards the end, we would find that they are contained in the training set verbatim, which is that it simply memorizes the training data.
Later, we will have sample methods that mitigate the pure regurgitation by a certain degree.
It is also worth noting that overfitting here occurs because we have a very, very small traing set and we iterate over it so many times. In pretraining modern LLMs today, overfitting is less of a concern, in fact, we might even want it to overfit.
Firstly, let's infer using greedy decoding
model.to("cpu")
model.eval()
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer),
max_new_tokens=25,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
'''
Output text:
Every effort moves you know," was one of the axioms he laid down across the Sevres and silver of an exquisitely appointed lun
'''As you can see, it clearly repeats some words in the training data. Now, when we test the same prompt again with temperature scaling and top-k sampling, we have.
def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):
# get logits, and only focus on last time step
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
# top_k sampling
if top_k is not None:
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(logits < min_val, torch.tensor(float("-inf")).to(logits.device), logits)
# temperature scaling
if temperature > 0.0:
logits = logits / temperature
probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
# greedy
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
if idx_next == eos_id: # Stop generating early if end-of-sequence token is encountered and eos_id is specified
break
# Same as before: append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
return idx
torch.manual_seed(123)
token_ids = generate(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer),
max_new_tokens=15,
context_size=GPT_CONFIG_124M["context_length"],
top_k=25,
temperature=1.4
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
'''
Output text:
Every effort moves you stand to work on surprise, a one of us had gone with random -
'''The result is somewhat more natural now.
Loading and Saving Model Weights. The recommended way in PyTorch is to save the model weights, the so-called state_dict via by applying the torch.save function to the .state_dict() method. We also might want to continue pretraining it in the future, therefore we must save the optimizer state too. Then we can load the model weights into a new GPTModel model instance as follows:
torch.save({
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
},
"model_and_optimizer.pth"
)
checkpoint = torch.load("model_and_optimizer.pth", weights_only=True)
model = GPTModel(GPT_CONFIG_124M)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0005, weight_decay=0.1)
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
model.train()Loading Pretrained Weights. While it is instructive to implement pretraining from scratch, training a useful GPT-2 model requires access to millions or billions of tokens and substantial computational resources. We acknowledges that our GPT is trained on a short story only for educational purposes. Pretraining a full-sized GPT-2 model on a large corpus would be cost-prohibitive, but OpenAI has released pretrained weights. We suggest downloading these weights and converting them to PyTorch format to bypass the heavy pretraining stage.
Pretraining a decoder-only language model involves several stages: tokenising raw text, segmenting it into fixed-length sequences, computing next-token prediction losses, iterating through batches to update the model, and sampling generated text to monitor progress. The pure PyTorch implementations help clarify the logic behind each function. All of the code in this post is supposed to be versatile and can be applied to continually pre-train other LLMs in the future.