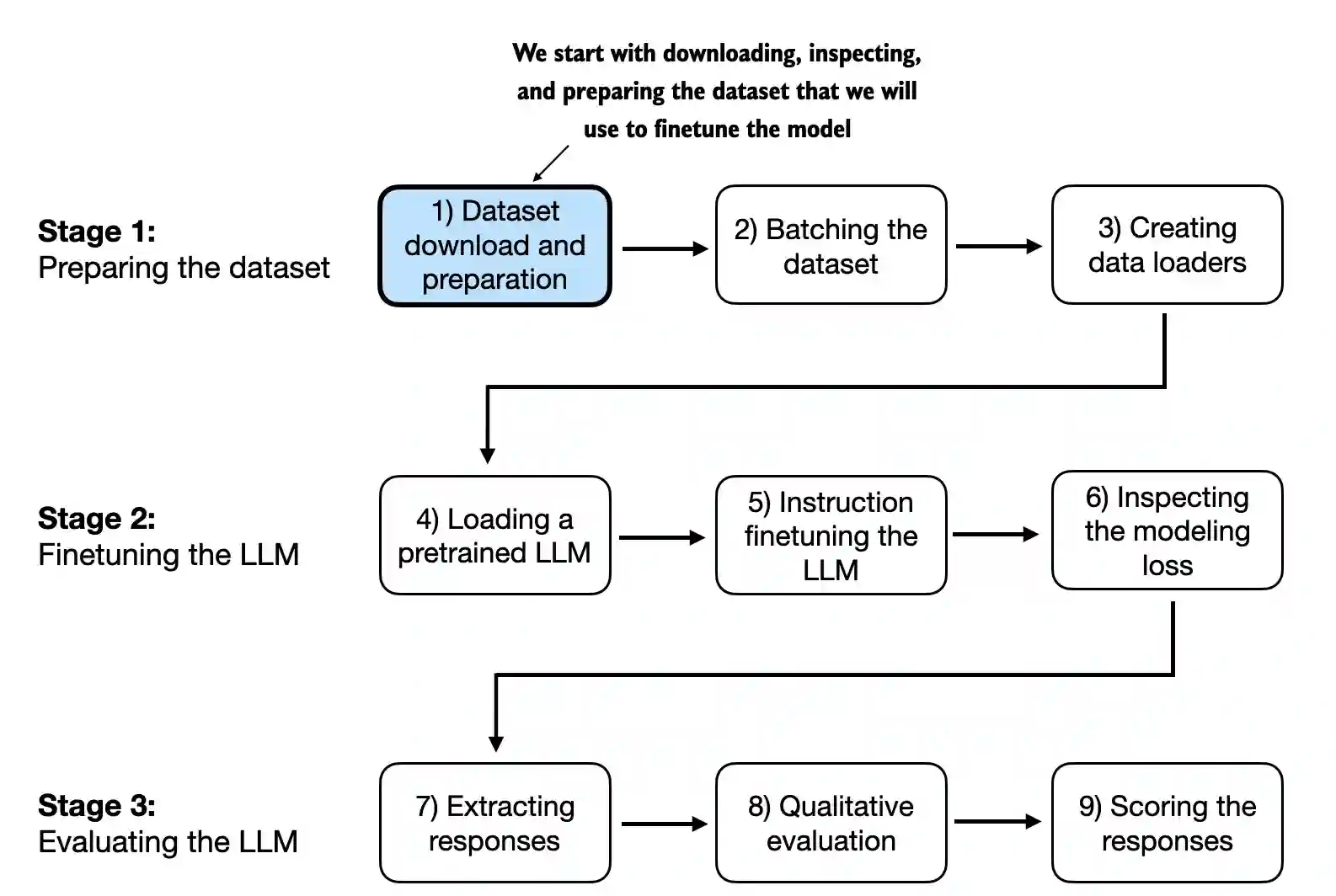
In this post I will lay out the complete pipeline for supervised finetuning (or instruction finetuning) a language model to follow instructions. Instruction fine-tuning is one of the main techniques behind developing LLMs for chatbot applications, personal assistants, and other conversational tasks.
The following is the whole pipeline, this pipeline can be implemented for other SFT tasks.
It is important to reiterate that preparing the dataset is a key aspect of instruction fine-tuning. This is the dataset what we are going to be working with. Here are some entries...
[
{
"instruction": "Evaluate the following phrase by transforming it into the spelling given.",
"input": "freind --> friend",
"output": "The spelling of the given phrase \"freind\" is incorrect, the correct spelling is \"friend\"."
},
{
"instruction": "Edit the following sentence for grammar.",
"input": "He go to the park every day.",
"output": "He goes to the park every day."
},
{
"instruction": "Convert 45 kilometers to meters.",
"input": "",
"output": "45 kilometers is 45000 meters."
},
]When training a languge model to talk and respond like a human, we must format the data accurately. In our case, we use Alpaca-style chat template, which was the original template for instruction finetuning.
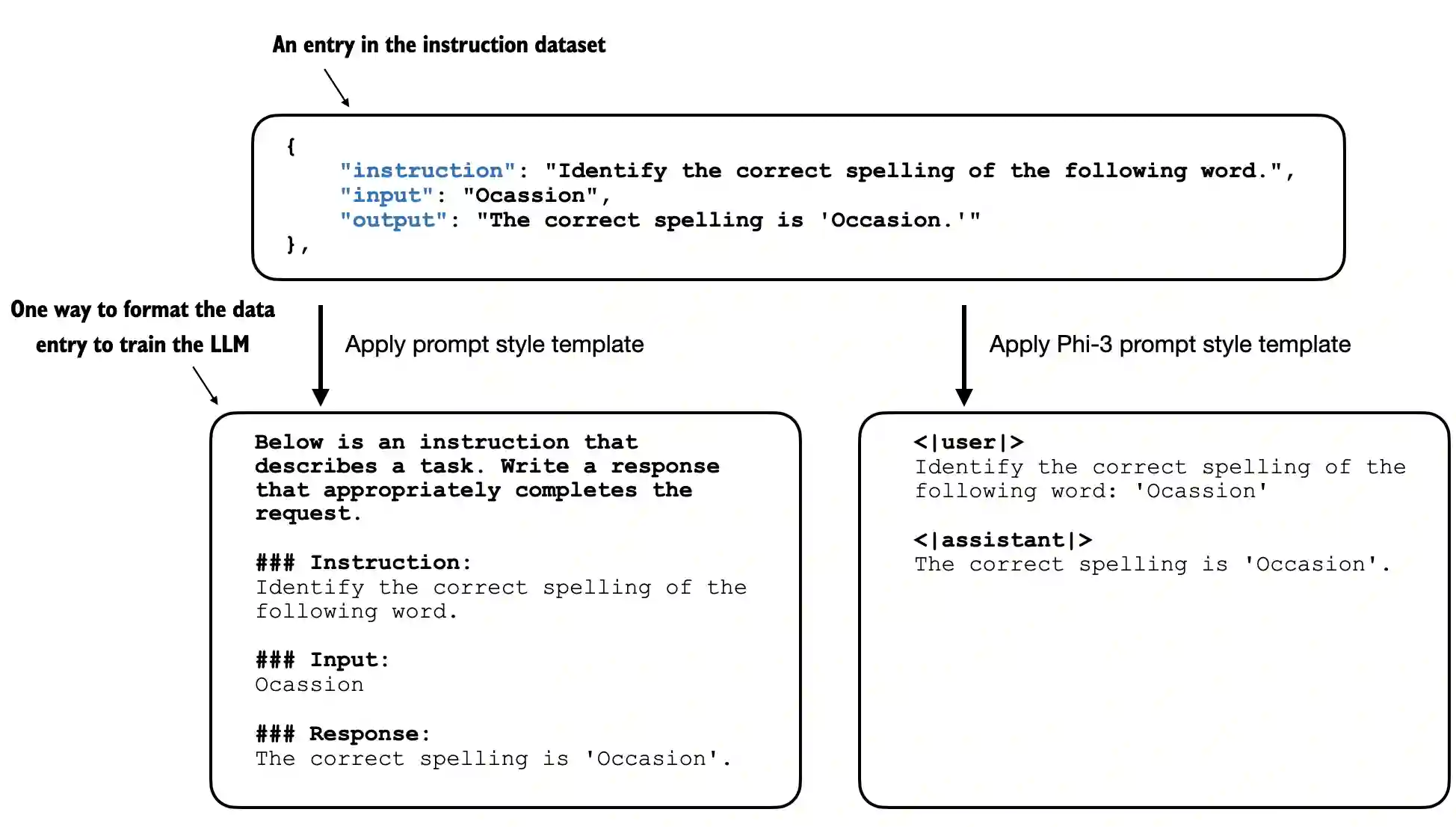
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
return instruction_text + input_text
'''
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify the correct spelling of the following word.
### Input:
Ocassion
### Response:
The correct spelling is 'Occasion.'
'''Again, before we prepare the PyTorch data loaders in the next section, we divide the dataset into a training, validation, and test set, hence some sanity checks. When SFT, we care about the total number of observations in the dataset
train_portion = int(len(data) * 0.85) # 85% for training
test_portion = int(len(data) * 0.1) # 10% for testing
val_portion = len(data) - train_portion - test_portion # Remaining 5% for validation
train_data = data[:train_portion]
test_data = data[train_portion:train_portion + test_portion]
val_data = data[train_portion + test_portion:]
print("Training set length:", len(train_data))
print("Validation set length:", len(val_data))
print("Test set length:", len(test_data))
'''
Training set length: 935
Validation set length: 55
Test set length: 110
'''Now, similar to when pre-training, we will tackle dataset batching in several steps, as illustrated below.
First, we implement an InstructionDataset class that pre-tokenizes all inputs in the dataset.
import torch
from torch.utils.data import Dataset
class InstructionDataset(Dataset):
def __init__(self, data, tokenizer):
self.data = data
# Pre-tokenize texts
self.encoded_texts = []
for entry in data:
instruction_plus_input = format_input(entry)
response_text = f"\n\n### Response:\n{entry['output']}"
full_text = instruction_plus_input + response_text
self.encoded_texts.append(
tokenizer.encode(full_text)
)
def __getitem__(self, index):
return self.encoded_texts[index]
def __len__(self):
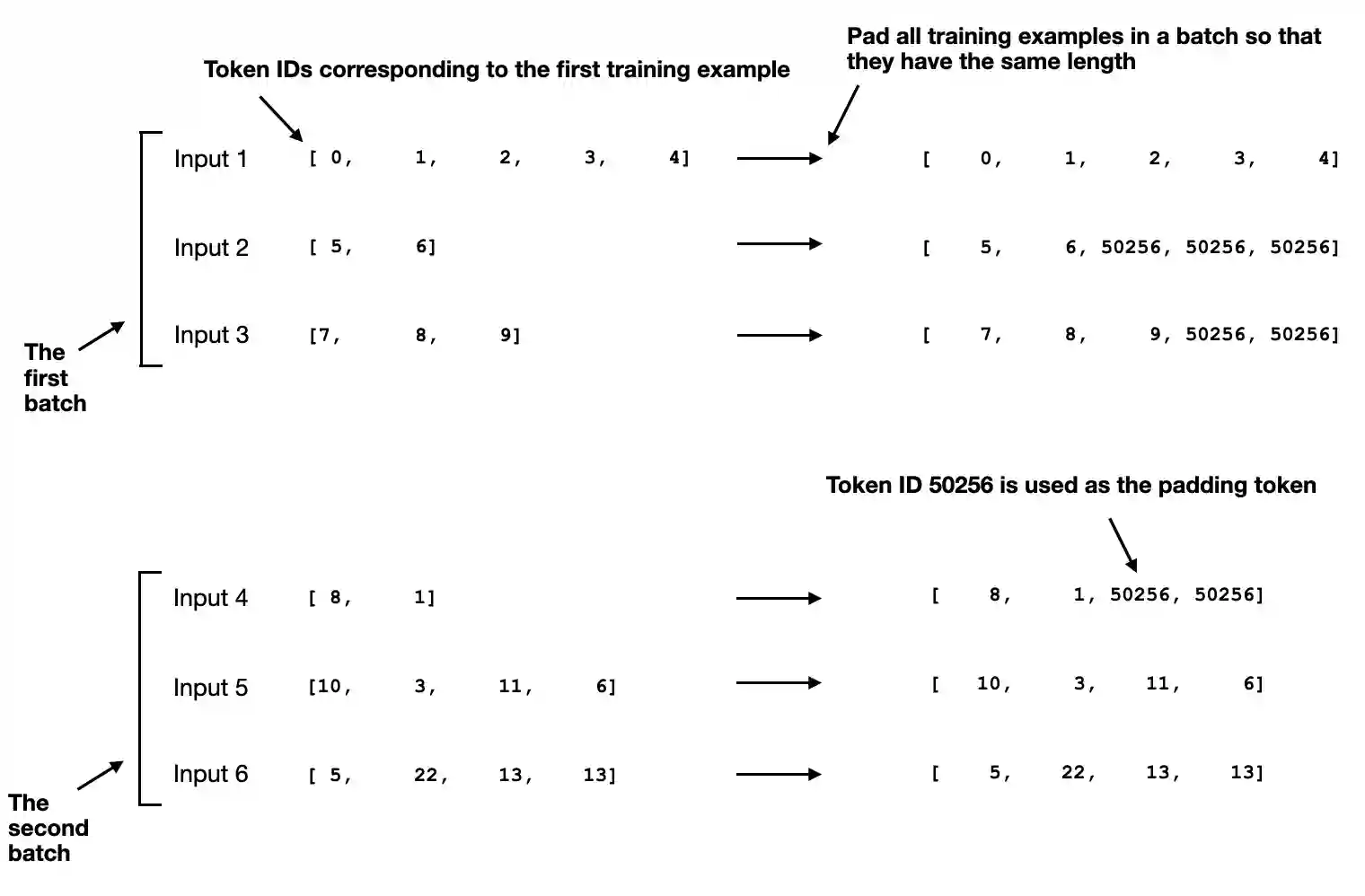
return len(self.data)Collate function. We obviously want to collect multiple training examples in a batch to accelerate training, and this requires padding all inputs to a similar length. A collate function serves this exact purpose. Also like pretraining, we use the <|endoftext|> token as a padding token.
There are two ways of padding. The simpler method is to pad ALL examples in a dataset to the same length (average, max). In our case, since we want to maximize efficiency, we will develop a custom "collate" function and then pass to the data loader. This custom collate function pads the training examples in EACH BATCH to have the same length (but different batches can have different lengths).
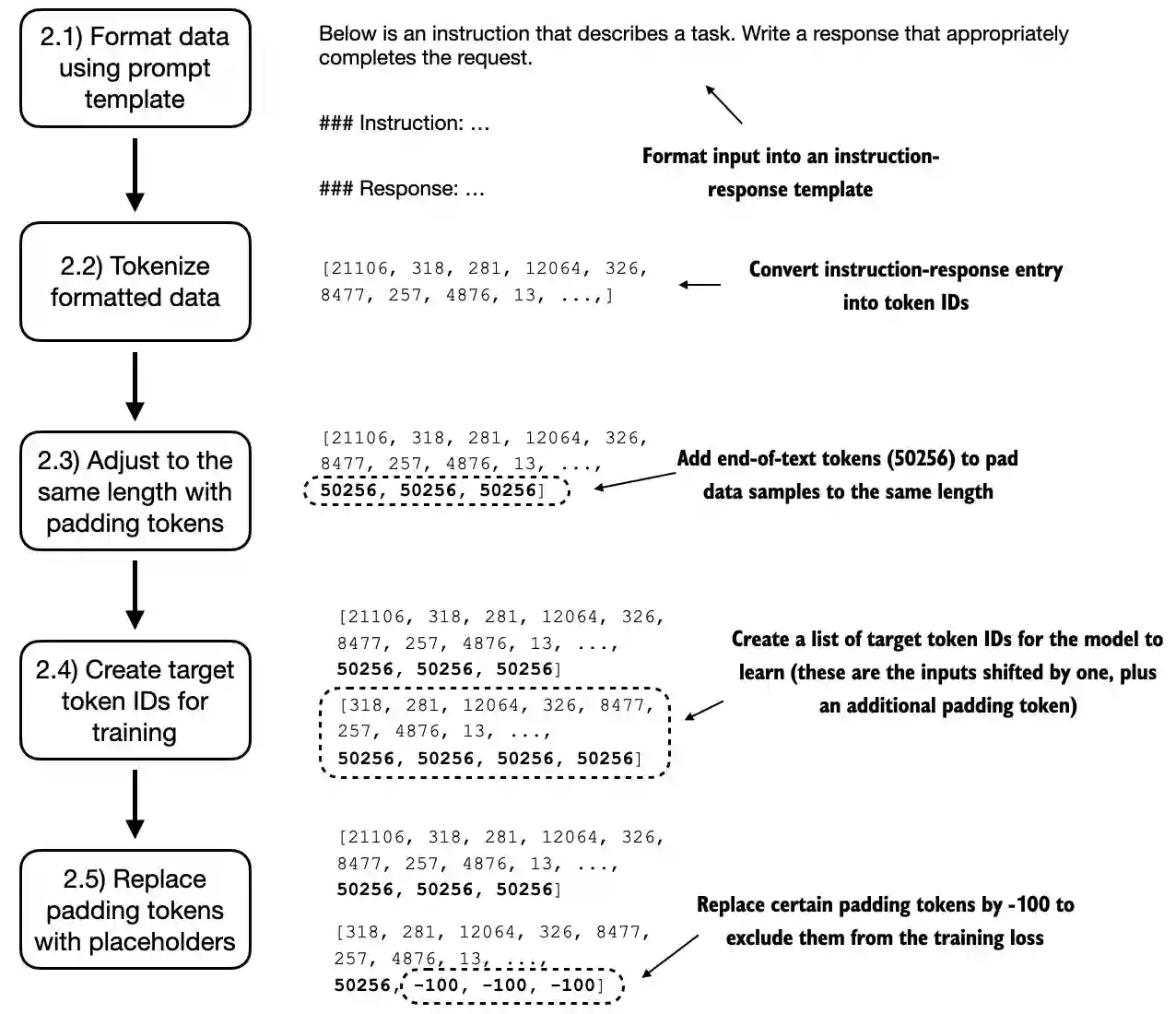
Sharing the same optimization objective the targets, when SFT an LLM, are the inputs (concatenated instruction, input, and output into a string of text) shifted by 1 position to the right, so the LLM learns to predict the next token
Now, we assign a -100 placeholder value to all padding tokens except the first padding token. This special value allows us to exclude these padding tokens from contributing to the training loss calculation, ensuring that only meaningful data influences model training.
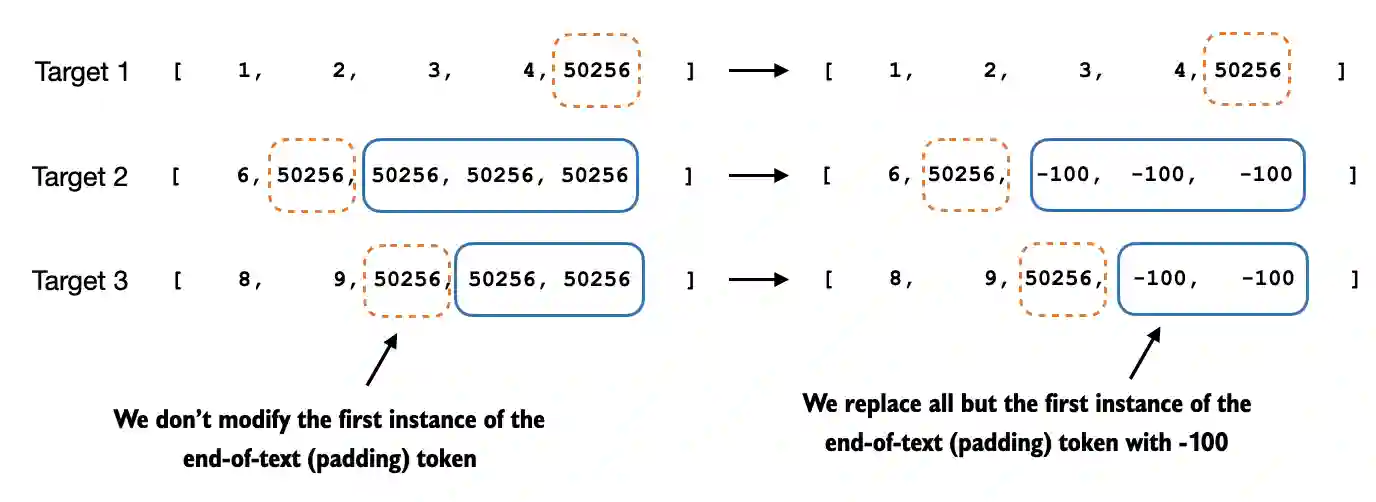
The reason why we retain an end-of-text token in the target list is because doing so allows the LLM learns when to generate an end-of-text token in response to instruction, which we use as a signal that the generated response is complete. This is to prevent issues like generating repeated texts, which is a very common problem.
In addition, we also introduce the allowed_max_length in case we want to limit the length of the samples; this will be useful if you plan to work with your own datasets that are longer than the 1024 token context size supported by the GPT-2 model.
def custom_collate_fn(
batch,
pad_token_id=50256,
ignore_index=-100,
allowed_max_length=None,
device="cpu"
):
# Find the longest sequence in the batch
batch_max_length = max(len(item)+1 for item in batch)
# Pad and prepare inputs and targets
inputs_lst, targets_lst = [], []
for item in batch:
new_item = item.copy()
# Add an <|endoftext|> token
new_item += [pad_token_id]
# Pad sequences to max_length
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs
targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets
# New: Replace all but the first padding tokens in targets by ignore_index
mask = targets == pad_token_id
indices = torch.nonzero(mask).squeeze()
if indices.numel() > 1:
targets[indices[1:]] = ignore_index
# New: Optionally truncate to maximum sequence length
if allowed_max_length is not None:
inputs = inputs[:allowed_max_length]
targets = targets[:allowed_max_length]
inputs_lst.append(inputs)
targets_lst.append(targets)
# Convert list of inputs and targets to tensors and transfer to target device
inputs_tensor = torch.stack(inputs_lst).to(device)
targets_tensor = torch.stack(targets_lst).to(device)
return inputs_tensor, targets_tensorIn practice, though not conclusively proven, it is also common to mask out the target token IDs that correspond to the instruction.

Another good detail is that we can now move the data to GPU (if available) instead of doing it in the main training loop, which improves efficiency because it can be carried out as a background process when we use the custom_collate_fn as part of the data loader. Using the partial function from Python's functools standard library, we create a new function with the device argument of the original function pre-filled
from functools import partial
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
customized_collate_fn = partial(
custom_collate_fn,
device=device,
allowed_max_length=1024
)Data Loader. We are now ready to instaniate the data loaders with the custom collate function.
from torch.utils.data import DataLoader
num_workers = 0
batch_size = 8
torch.manual_seed(123)
train_dataset = InstructionDataset(train_data, tokenizer)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=True,
drop_last=True,
num_workers=num_workers
)
val_dataset = InstructionDataset(val_data, tokenizer)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=False,
drop_last=False,
num_workers=num_workers
)
test_dataset = InstructionDataset(test_data, tokenizer)
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=False,
drop_last=False,
num_workers=num_workers
)
print("Train loader:")
for inputs, targets in train_loader:
print(inputs.shape, targets.shape)
'''
Train loader:
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 73]) torch.Size([8, 73])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 72]) torch.Size([8, 72])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 62]) torch.Size([8, 62])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 62]) torch.Size([8, 62])
torch.Size([8, 68]) torch.Size([8, 68])
'''Loading Pretrained Model. This part is self-explanatory. We load the 355M version to obtain decent performance.
from helper import download_and_load_gpt2
from gpt_model import GPTModel, load_weights_into_gpt
BASE_CONFIG = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"drop_rate": 0.0, # Dropout rate
"qkv_bias": True # Query-key-value bias
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
CHOOSE_MODEL = "gpt2-medium (355M)"
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
settings, params = download_and_load_gpt2(
model_size=model_size,
models_dir="gpt2"
)
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval()It is never redundant to infer the base model before carrying out any training.
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer),
max_new_tokens=35,
context_size=BASE_CONFIG["context_length"],
eos_id=50256,
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
print(response_text)
'''
The chef cooks the meal every day.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the
'''It can be clearly seen that the model is not capable of following instructions yet; it creates a 'Response' section but simply repeats the original input sentence as well as the instruction.
The final sanity check is to compute the untrained loss.
model.to(device)
torch.manual_seed(123)
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
'''
Training loss: 3.8259087562561036
Validation loss: 3.761933708190918
'''Training. Let's train the model now, we use the same training function as in pre-training since they share the same aim.
import time
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.00005, weight_decay=0.1)
num_epochs = 2
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context=format_input(val_data[0]), tokenizer=tokenizer
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")
'''
Ep 1 (Step 000000): Train loss 2.637, Val loss 2.626
Ep 1 (Step 000005): Train loss 1.174, Val loss 1.103
Ep 1 (Step 000010): Train loss 0.872, Val loss 0.944
Ep 1 (Step 000015): Train loss 0.857, Val loss 0.906
Ep 1 (Step 000020): Train loss 0.776, Val loss 0.881
Ep 1 (Step 000025): Train loss 0.754, Val loss 0.859
Ep 1 (Step 000030): Train loss 0.800, Val loss 0.836
Ep 1 (Step 000035): Train loss 0.714, Val loss 0.809
Ep 1 (Step 000040): Train loss 0.672, Val loss 0.806
Ep 1 (Step 000045): Train loss 0.633, Val loss 0.789
Ep 1 (Step 000050): Train loss 0.663, Val loss 0.782
Ep 1 (Step 000055): Train loss 0.760, Val loss 0.763
Ep 1 (Step 000060): Train loss 0.719, Val loss 0.743
Ep 1 (Step 000065): Train loss 0.653, Val loss 0.735
Ep 1 (Step 000070): Train loss 0.536, Val loss 0.732
Ep 1 (Step 000075): Train loss 0.569, Val loss 0.739
Ep 1 (Step 000080): Train loss 0.603, Val loss 0.734
Ep 1 (Step 000085): Train loss 0.518, Val loss 0.717
Ep 1 (Step 000090): Train loss 0.575, Val loss 0.699
Ep 1 (Step 000095): Train loss 0.505, Val loss 0.689
Ep 1 (Step 000100): Train loss 0.507, Val loss 0.683
Ep 1 (Step 000105): Train loss 0.570, Val loss 0.676
Ep 1 (Step 000110): Train loss 0.564, Val loss 0.671
Ep 1 (Step 000115): Train loss 0.522, Val loss 0.666
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is prepared every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive:
Ep 2 (Step 000120): Train loss 0.439, Val loss 0.671
Ep 2 (Step 000125): Train loss 0.454, Val loss 0.685
Ep 2 (Step 000130): Train loss 0.448, Val loss 0.681
Ep 2 (Step 000135): Train loss 0.406, Val loss 0.678
Ep 2 (Step 000140): Train loss 0.412, Val loss 0.678
Ep 2 (Step 000145): Train loss 0.372, Val loss 0.680
Ep 2 (Step 000150): Train loss 0.381, Val loss 0.674
Ep 2 (Step 000155): Train loss 0.419, Val loss 0.672
Ep 2 (Step 000160): Train loss 0.417, Val loss 0.680
Ep 2 (Step 000165): Train loss 0.383, Val loss 0.683
Ep 2 (Step 000170): Train loss 0.328, Val loss 0.679
Ep 2 (Step 000175): Train loss 0.334, Val loss 0.668
Ep 2 (Step 000180): Train loss 0.391, Val loss 0.656
Ep 2 (Step 000185): Train loss 0.418, Val loss 0.657
Ep 2 (Step 000190): Train loss 0.341, Val loss 0.648
Ep 2 (Step 000195): Train loss 0.330, Val loss 0.633
Ep 2 (Step 000200): Train loss 0.313, Val loss 0.631
Ep 2 (Step 000205): Train loss 0.354, Val loss 0.628
Ep 2 (Step 000210): Train loss 0.365, Val loss 0.629
Ep 2 (Step 000215): Train loss 0.394, Val loss 0.634
Ep 2 (Step 000220): Train loss 0.301, Val loss 0.647
Ep 2 (Step 000225): Train loss 0.347, Val loss 0.661
Ep 2 (Step 000230): Train loss 0.297, Val loss 0.659
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is cooked every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What is the capital of the United Kingdom
Training completed in 0.93 minutes.
'''We can see the decreasing training loss and validation loss as well as more accurate responses.
Evaluation. This is the new part where we will use a local model gpt-oss-20b: on Ollama to evaluate our finetuned model's results on test data. Firstly, let's save the model's predictions into a JSON file.
from tqdm import tqdm
for i, entry in tqdm(enumerate(test_data), total=len(test_data)):
input_text = format_input(entry)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = generated_text[len(input_text):].replace("### Response:", "").strip()
test_data[i]["model_response"] = response_text
with open("instruction-data-with-response.json", "w") as file:
json.dump(test_data, file, indent=4) # "indent" for pretty-printingPlease follow the subsequent code for a complete setup
import psutil
def check_if_running(process_name):
running = False
for proc in psutil.process_iter(["name"]):
if process_name in proc.info["name"]:
running = True
break
return running
ollama_running = check_if_running("ollama")
if not ollama_running:
raise RuntimeError("Ollama not running. Launch ollama before proceeding.")
print("Ollama running:", check_if_running("ollama"))
'''
Ollama running: True
'''import urllib.request
def query_model(
prompt,
model="llama3",
url="http://localhost:11434/api/chat"
):
# Create the data payload as a dictionary
data = {
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"options": {
"seed": 123,
"temperature": 0,
"num_ctx": 2048
}
}
# Convert the dictionary to a JSON formatted string and encode it to bytes
payload = json.dumps(data).encode("utf-8")
# Create a request object, setting the method to POST and adding necessary headers
request = urllib.request.Request(
url,
data=payload,
method="POST"
)
request.add_header("Content-Type", "application/json")
# Send the request and capture the response
response_data = ""
with urllib.request.urlopen(request) as response:
# Read and decode the response
while True:
line = response.readline().decode("utf-8")
if not line:
break
response_json = json.loads(line)
response_data += response_json["message"]["content"]
return response_dataAnd finally, we output the score made by the strong model to our SFT model.
def generate_model_scores(json_data, json_key, model="llama3"):
scores = []
for entry in tqdm(json_data, desc="Scoring entries"):
prompt = (
f"Given the input `{format_input(entry)}` "
f"and correct output `{entry['output']}`, "
f"score the model response `{entry[json_key]}`"
f" on a scale from 0 to 100, where 100 is the best score. "
f"Respond with the integer number only."
)
score = query_model(prompt, model)
try:
scores.append(int(score))
except ValueError:
print(f"Could not convert score: {score}")
continue
return scores
scores = generate_model_scores(test_data, "model_response")
print(f"Number of scores: {len(scores)} of {len(test_data)}")
print(f"Average score: {sum(scores)/len(scores):.2f}\n")
'''
Scoring entries: 100%|████████████████████████| 110/110 [01:10<00:00, 1.57it/s]
Number of scores: 110 of 110
Average score: 50.32
'''Our model achieves an average score of above 50, which we can use as a reference point to compare the model to other models or to try out other training settings that may improve the model.
Refer to this pipeline when you need to do instruction finetuning to other open-source models.