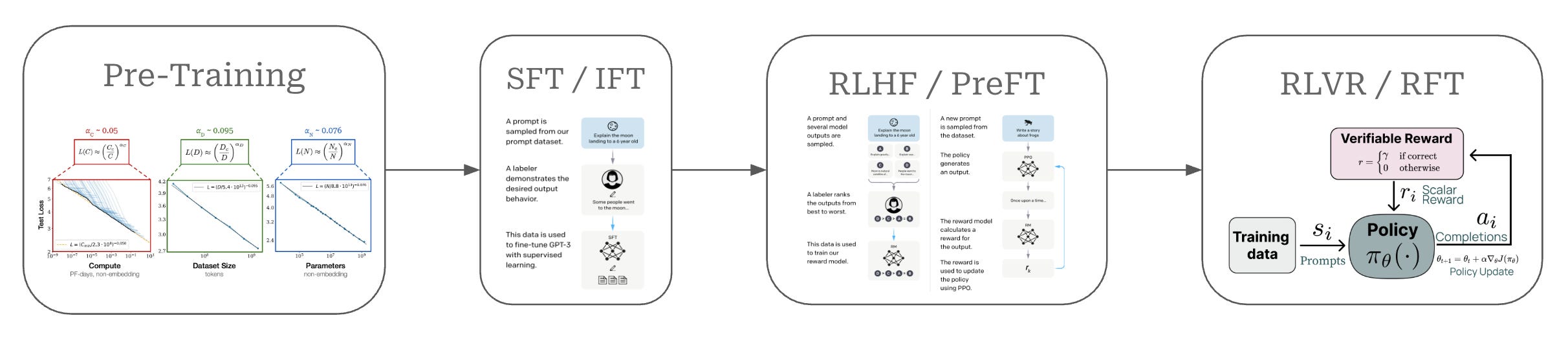
OpenAI's gpt-oss family marks a major milestone: it's the company's first open-weight release since GPT-2 in 2019. The family currently comprises two decoder-only models, gpt-oss-20b and gpt-oss-120b, that were designed specifically for efficient agentic work. This is especially important: the oss family is optimized for agentic workflows.
I would like to decicate this post to:
- Providing a comprehensive review of every single technical detail revealed about GPT-oss in the original reports by OpenAI
- Explaining how each of these details work from the ground up.
This is a technical post talking about all the current state-of-the-art techniques inherent in frontier LLMs. Understanding this will form a better perspective on the state of LLM research at OpenAI.
Keywords: Mixture-of-experts (MoE), quantization-aware training, mixed precision, chain-of-thought (CoT), Harmony prompt format, context lenght, reinforcement finetuning, safety alignment.

"They were trained using a mix of reinforcement leanring and techniques informed by OpenAI's most advanced internal models, including o3 and other frontier system."
The GPT-oss release includes two versions of models: 20b and 120b respectively. These are MoE-based reasoning models that are text-only and primarily trained on English data. Their MoE architecture and quantization-aware training enable them to be extremely compute and memory-efficient. The 20b and 120b models have 5b and 3.5b active parameters respectively. Using MXFP4 (~4-bit) precision, the larger model can be hosted on a single 80GB GPU, while GPT-oss-20b needs only ~16GB of memory for hosting. These models are extensively post-trained to optimize their chain of thought (CoT) reasoning and safety.
Agentic workflow: as mentioned earlier, both oss models are suitable for being the brains of the AI agents with a reasonably long context window of 131k tokens, as well as proficient tool use, reasoning and instruction-following capabilities. In addition, they are incorporated with the new Harmony prompt format-a flexible, hierarchical chat template capable of capturing diverse LLM interaction patterns-for training and interacting. The GPT-oss models also provide the ability to adjust their reasoning effort (i.e., to low, medium or high effort levels) by explicitly specifying an effort level in their system message.
Public reception: While the release of GPT-OSS models has generated significant excitement, the reality is that many in the tech community feel the models have not fully lived up to expectations. Yes they are definitely not the best models ever, but they are open weight models released by one of the top LLM labs in the world. Given that circumstance, we would be foolish not to play with these models and undertand how they work.
Model Architecture
The GPT-oss models are autoregressive Mixture-of-Experts (MoE) transformers that build upon the GPT-2 and GPT-3 architectures. This section starts with the basic understanding of the transformer and then outlines each unique component of the oss family with some general explanation.
Transformer ModelA depiction of a standard, decoder-only transformer architecture is provided above. This architecture is almost universally used by all modern GPT-style LLMs.
Embedding dimension. Obviously, the input to the model is a sequence of token ids corresponding to token vectors stacking together to form a matrix. In case of the GPT-oss models, the embedding dimension is 2880, and this dimension is fixed throughout all the layers.
Block structure: they contain repeated decoder blocks (24 for the 20B version and 36 for the 120B version). As depicted above, all of the blocks maintain consistent components: masked multi-headed self-attention, feed-forward layer, normalization, and residual connection. Initially introduced by GPT-2, the GPT-oss models adopt a pre-normalization structure. This means that the normalization layers in the decoder block are placed before both the attention and feed-forward layers, yielding the following structure:
Decoder Block Input -> Normalization -> Masked Self-attention -> Residual Connection -> Normalization -> Feed-forward Layer -> Residual Connection -> Decoder Block Output.
Nevertheless, debates do ensue over whether pre-normalization is actually superior.
Normalization. Early transformers used layer normalization as the standard choice of normalization layer. Recently, however, many LLMs have replaced it with root mean square layer normalization (RMSNorm), which is a simpler and more computationally efficient version of the layer normalization with fewer trainable parameters while keeping consistent performance.
Mixture-of-Experts (MoE)
Context Management
Training Process